SPA(Single Page Application)におけるSEO対策の覚書です。
目次
はじめに
ウェブアプリがSPAとして構築されるケースが増えて来ている中、俄然SPAにおけるSEO対策は年々重要視されるようになっています。
世界でも有数の検索エンジンであるGoogle が提供する検索エンジンクローラーのGoogle bot も、2014年にはJavaScriptによるレンダリングを試みることを発表しました。
それまでは_escaped_fragment_を用いてクローラー判定を行い、プリレンダリングされたHTMLを返却するというクローリング対策が推奨されてきましたが、一転してGoogle bot 専用のページを事前にレンダリングしておく事は非推奨となりました。
そして2018年現在ではGoogle bot はChrome 41相当のレンダリング能力を有しており、事実ある程度のJavaScriptは解釈されるようになりました。
では実際、エンジニアやウェブ担当の痛みは取り除かれたでしょうか。控えめに言ってもインデックスが満足に行われているとは言えない状況が続いているかと思います。
Chrome 41 以降にリリースされたAPI は数多く存在しますが、当然の事ながらクローラーはその全てを理解することが出来ません。今現在のバージョン(※2018/12時点でver.71)が搭載しているAPIと同等の環境を再現しようとした場合は大量のポリフィルを準備する必要があります。
併せてGoogle bot を含むすべての検索クローラがアプリケーションを正しく解釈出来るような状況を作り出すためには、考慮すべき点が無数に存在しているため、実現するためには未だ相当のコストをかけなければならないのが実情です。
これらの状況を加味すると、作成したSPAを正しくクローラーに認識させるためには、2018年現在でも予め完成されたHTMLを確実にクローラーに提供するほうが良いということとなります。
残念ながら、index.htmlをクローラにぶん投げればOK!という未来には到達していないのです。
サーバーサイドレンダリング
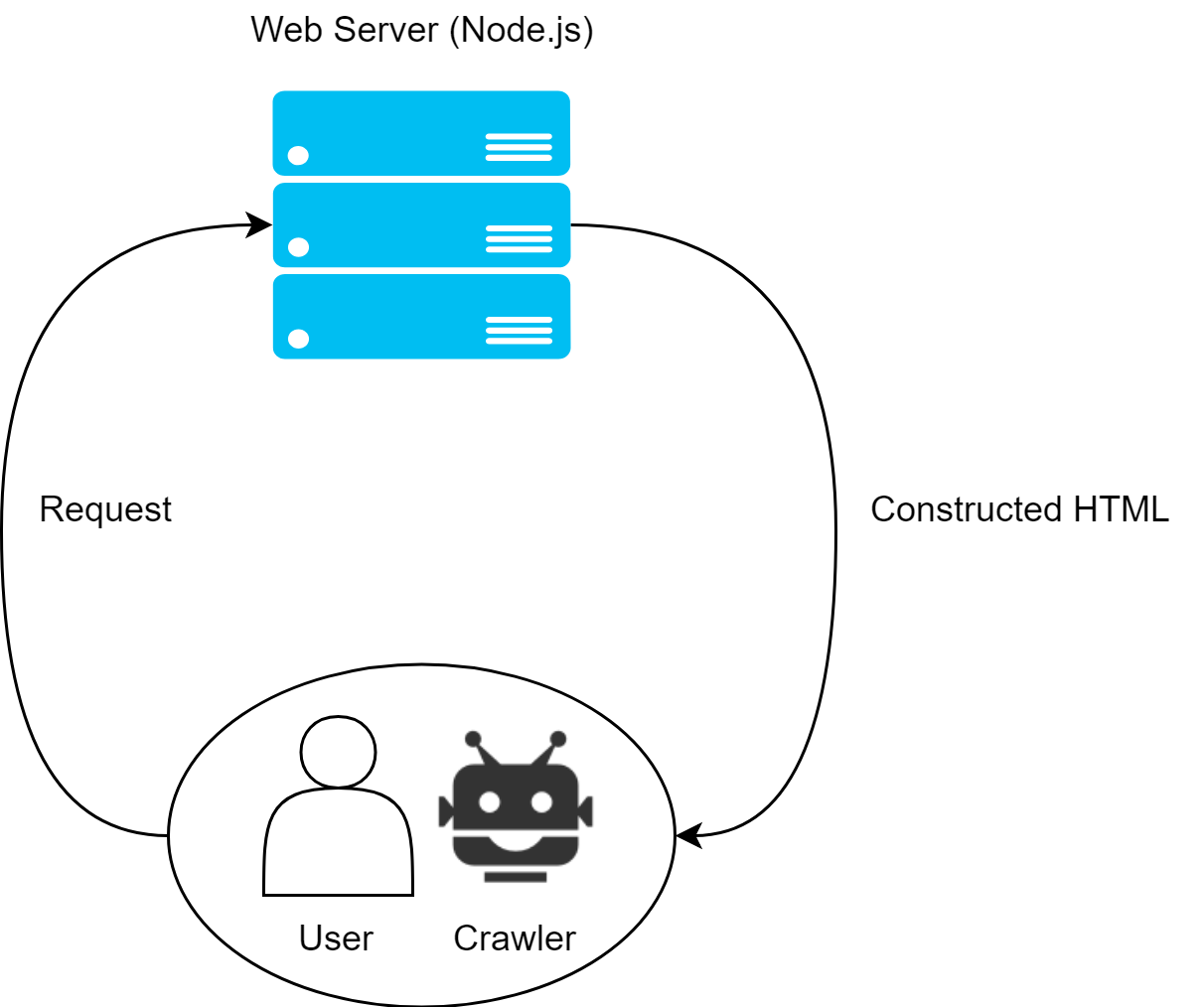
サーバーサイドレンダリング(SSR)とは、WebサーバーによってHTMLをレンダリングし、クライアントに完成したビューを返却する手法です。
Angular、React、Vue.js、又他の同様のフレームワークの場合、仮想DOMに対してアプリを実行しHTMLを構築、最終的に仮想DOMをHTML文字列に変換してからクライアントへ返却します。
コンテンツがブラウザへ到達した後に、各フレームワークは既存のコンテンツをシームレスにマウントするので、その後のルーティング処理やイベント等もクライアントサイドレンダリングと同様に問題なく動作します。
そして何よりサーバーより返却されるHTMLは既に完成されているため、クローラーフレンドリーである可能性が高まるのです。
しかしサーバーサイドレンダリングには次のようなデメリットも存在します。
- バックエンドがNode.js 環境に限られる。
- ※Node.js 以外のバックエンドはPHP のv8js エクステンション等があるが、いずれにせよ環境は限られる。
- SSRの実装は複雑かつ高コスト。プロジェクトによっては非常に多くの追加開発時間が必要となる。
- サーバーへのリクエスト毎にレンダリング処理が実行されるため、高性能なインフラが要求される。
- ※これに関してはキャッシングで対策したり等、軽減出来る部分が多い。
- クライアント(ブラウザ)が解釈するスクリプトと、サーバー(Node.js)が解釈するスクリプトに相違が無いように実装する必要がある。例えば
windowオブジェクトの利用が前提であるアプリケーションは正常に動作しません。
実装コストの観点から、Nuxt.js のようなサーバーサイドレンダリングの機構を最初から搭載しているフレームワークを選択しても良いかもしれません。
プリレンダリング
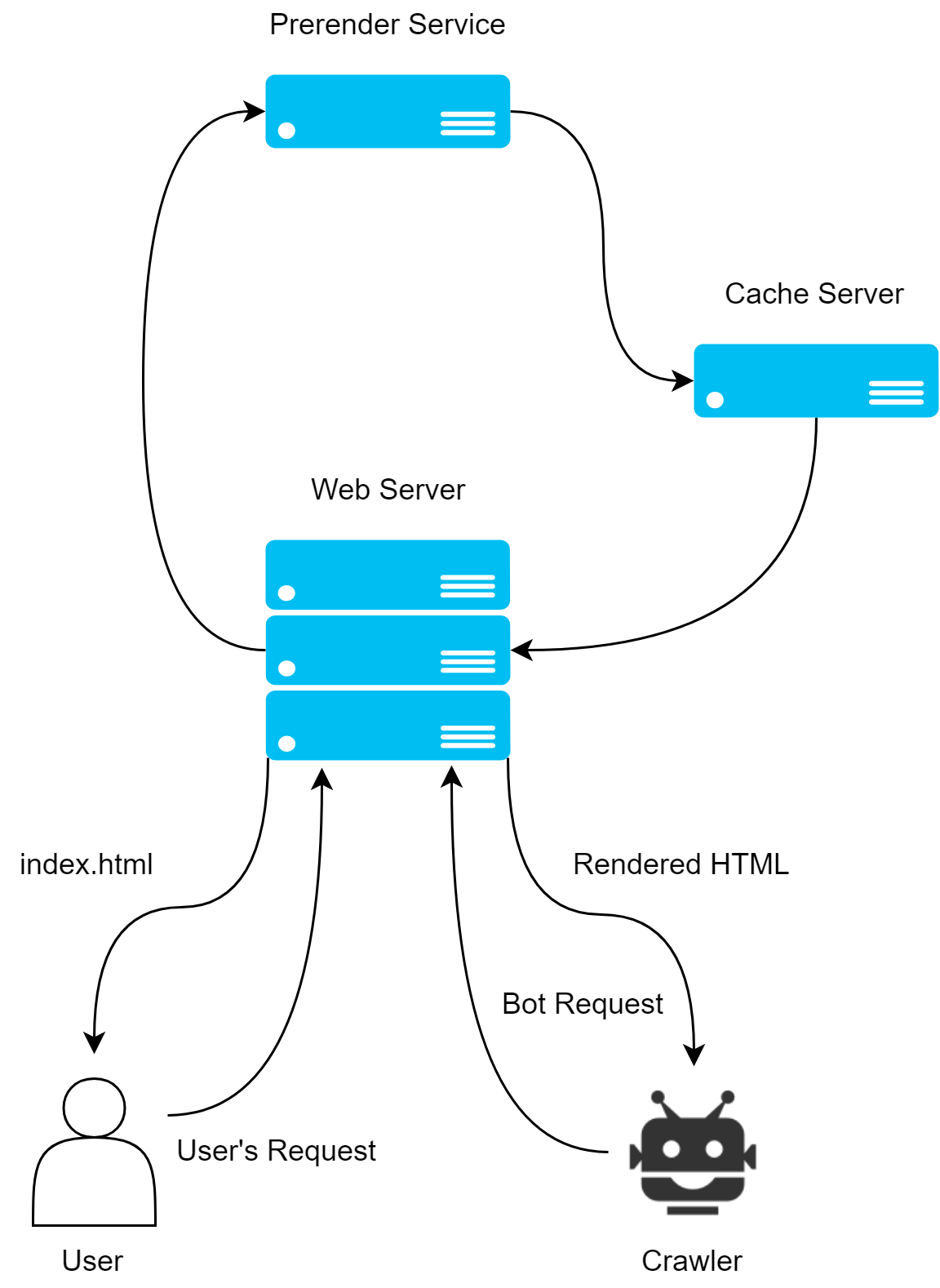
プリレンダリングは、静的なHTMLを予めレンダリングしておき、クライアントからリクエストを受け取った際に、レンダリング済みのHTMLを返却する手法です。
このアプローチでは、ヘッドレスブラウザを用いてアプリケーションを実行しHTMLを構築します。生成されたHTMLをスナップショット(キャッシュ)として保持しておくことで、クライアントからのリクエストに高速に応答することが出来ます。
prerender.ioやrendertronといったヘッドレスブラウザを用いて実現します。
当然、HTMLは完成された状態であるためクローラーには従来のWebページ(SPAでないアプリ)と同様であるように見せることが出来ます。
クローラーフレンドリーであることはもちろん、Node.js の実行環境が不要、クローラーが搭載するJavaScriptのAPI レベルの考慮が不要、実装が容易、静的HTMLを返却するだけのため標準性能なインフラで十分運用可能、といった具合にたくさんのメリットを享受出来ます。
一方デメリットとしては次のような物が挙げられます。
- ステートフルなページでは適用出来ない
- ユーザーのアカウントページといった固有の情報をレンダリングする必要のあるページ
- ルーティングの数が膨大な大規模なサイト
- プリレンダリングは予め静的HTMLの生成処理を走らせる必要があるため、そのページ数や更新頻度によっては非現実的な時間が掛かってしまう可能性があります。
しかしこれらのデメリットを許容出来る状況であれば、プリレンダリングはSPAのSEO対策における強力な選択肢の中の一つであると言えます。
クローラーに対して専用のビューを返却する行為は、いわゆる「クローキング」に該当するのではないか?との声もありますが、最終的に生成されるHTMLがクライアントサイドレンダリングのものと大差なければ全く問題は無いようです。
「Don’t Be Evil」の精神を貫きましょう。
結論
検索エンジンクローラーはここ数年だけでも目覚ましい進化を遂げていますが、Google bot でさえ最新のスクリプトを正しく解釈する事は難しく、依然としてエンジニア側での対応が必要不可欠であると言えます。
SSR やプリレンダリングといった手法の良し悪しは、プロジェクトの規模、状況、により大きく変化するため、何が最適であるかは各々が見極めた上で丁寧に対応していく必要があるでしょう。